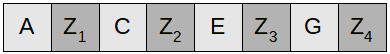
Overview
This concept of a file storing other files is very common and you see/use them everyday without even realizing it. These files can be thought of as "mini-filesystems" because the files they operate on are just wrappers for many other files contained within. For example:
and you'll see a directory of all files in the file. If you want to test the integrity of all of the files in the archive, use the -t option:unzip -lv filename
unzip -t filename
Applications that distribute many files will often wrap them all into one really large file. It's much easier to manage a single file than thousands of separate ones. Some examples (from my youth!)
The most fundamental property of a filesystem is that it is just a data structure, not unlike a linked list or array. In fact, some of the earliest filesystems were simple arrays and linked lists. The complexity of the data structure is directly related to the size, performance (speed), and information stored in the filesystem. Because not all systems require the same level of performance, there are hundreds of different filesystems.
Some are very simple and others are massively complex. Think of an iPod or TiVo or even a cell phone. The number of files these devices contain may be measured in the thousands (103). These devices have radically different needs than say the server farms at Google or Facebook, where the number of files are measured in the billions (109) and beyond. Those filesystems contain millions of terabytes of data as well. Most home users don't have anywhere near this kind of requirement.
To help understand the problems and challenges that filesystem developers are trying to solve, we will build a simple, yet effective, filesystem that can work for small-scale devices. After completing it, we will look at many other features that can be added to make it faster, more scalable, and more reliable and resilient.
Here is some of the information that we will need to store about a file:
The goal of this is not to create a Real-World™ Filesystem, but to understand how they work and can be implemented.
Simplified view of a very simple filesystem (One Big File):
BTW, the reason we are not going to try to implement a modern filesystem (or even a partial one) is simply the sheer complexity. Take a look at what the primary file system is for Windows: NTFS Specs (local copy in case the link is dead.) Just look at the hundreds and hundreds of options and details for that file system. Compare that to a "trivial" FAT-type file system and you can see how far they've come.
Basic Structure
At the most basic level, each file is going to be represented by a singly-linked list of blocks. The disk block is the smallest unit that can be read/written by the filesystem. Typical block sizes in bytes are 512, 1K, 2K, 4K, 8K ... up to 64K. Another term you will hear for block is sector.So, for example, a file that is 1,400 bytes that is stored in a fileystem with 512 byte blocks will require 3 blocks. The first 2 blocks will be full, totaling 1024 bytes (512 * 2) and the third block will store the "residual" 376 bytes (with 136 bytes unused). Logically, the blocks will be stored as a linked-list of 3 blocks:
Our filesystem is going to be loosely based on the original FAT (File Allocation Table) filesystem that was used by MSDOS back in the 1980s. The FAT filesystem is arguably still the most popular filesystem in use today, although it has been modified somewhat (VFAT, FAT32, exFAT) to deal with the technological demands of newer devices. e.g. larger drives, long filenames, very large files, etc.
We'll call the filesystem SFAT for Simple FAT because, although the original FAT filesystem was very simple, ours is going to be even simpler. Remember, this is an instructional video! You are not going to go out and replace Google's filesystem anytime soon!
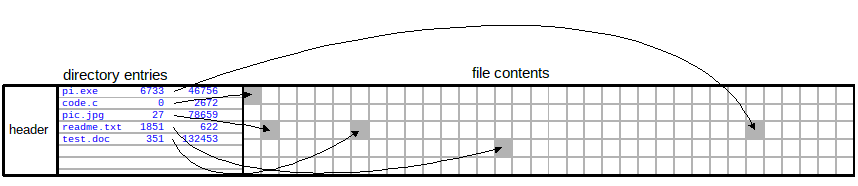
The SFAT filesystem will have 4 basic sections. These sections are the
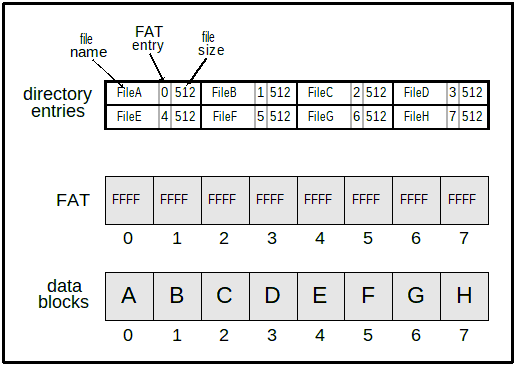
The relationship between the directory entry, file allocation table, and data blocks.
Close-up of the FAT entries: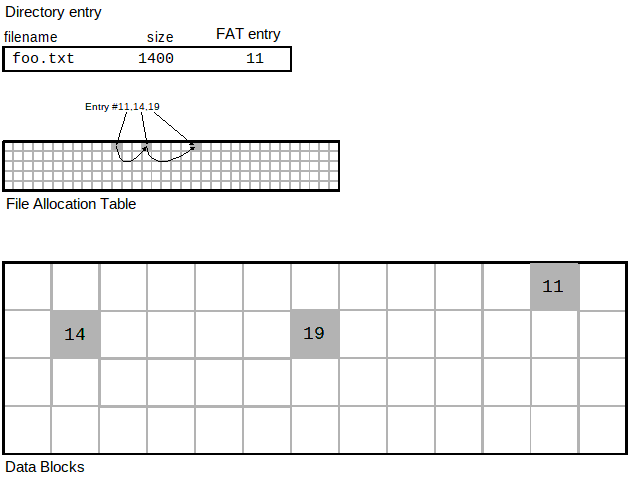
Given this configuration for the filesystem:
Here are some values:
Attribute Value total_sectors 8192 sectors_per_cluster 1 bytes_per_sectors 512 total_direntries 1024
Details of the super block:
| Diagram | SuperBlock C structure | |
|---|---|---|
|
|
|
Details of a directory entry:
There will be an array of directory entries. The number of elements in the array is the number of directory entries specified when the filesystem was created.
| Diagram | DirEntry C structure | |
|---|---|---|
|
|
|
superblock directory area FAT area data area
32 + 16,384 + 16,384 + 4,194,304 = 4,227,104
We can also see the limitations of the filesystem based on this structure:
The diagram below shows the relationship between the file allocation table and the data area (using the numbers from above). There is exactly one FAT entry for each data block in the filesystem. This is what the FAT and data area would look like immediately after creation (and before any files are stored):
Note that the size of the super block is always 32 bytes and the size of each directory entry is always 16 bytes. What varies are the number of sectors (total_sectors), sectors_per_cluster, the size of each sector (bytes_per_sector), and the number of directory entries (total_direntries).With most linked lists you've been dealing with, you normally have a "next" pointer as part of the node (block). In this case, there are no next pointers stored in each data block. Instead, the file allocation table is used for that purpose. You can think of the FAT as an array of all of the next pointers that would be stored in the data blocks. That's why there is a one-to-one correspondence with the number of FAT entries, and the number of data blocks. We are simply storing the "next" pointers outside of the data blocks themselves. This means that the data blocks are storing only data; not any next pointers or other information. The diagrams below will clarify this.
In essence:
Note: Some filesystems do not put a limit on the number of files that a filesystem can contain because the directory area can grow. To keep things manageable for our simple filesystem, we have a fixed-size directory area that is set when the filesystem is created and cannot grow at a later time. Once the directory entries are all in use, the file system can be considered "full", even if there are more data blocks available.
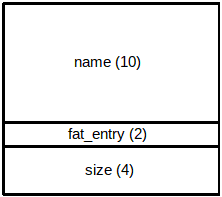
Directory entry (16 bytes in size, 10/2/4):
You may realize that the file is not fragmented, meaning, all of the data blocks are contiguous. This is not guaranteed and is usually not the case, especially with a lot of activity like deleting files and adding files. It is entirely possible that the filesystem could end up looking more like this after a bunch of activity: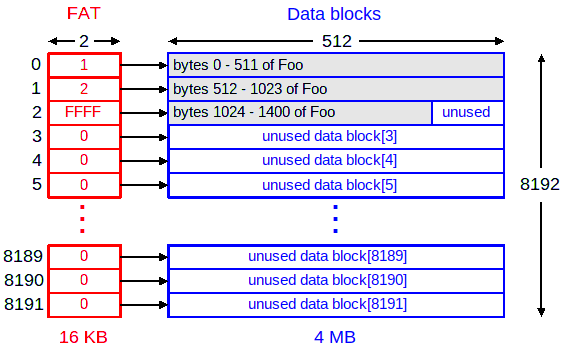
Directory entry:
Self-check:
1. How does the filesystem know how many bytes are stored in the last block (the "residual" bytes) since that information isn't in the FAT nor the data block itself?
2. What happens with the remaining unused bytes in the last data block?
3. What can you say about the size of file A?
4. What can you say about the size of file B?
Creating the Filesystem
Let's create an empty filesystem so we can add files to it. After creating the empty filesystem using the configuration parameters above, this is what a raw dump of the filesystem looks like. Since there are no files stored yet, only the super block has any information.
| Raw filesystem dump (240 bytes) | Super block information (32 bytes) | |
|---|---|---|
00 01 02 03 04 05 06 07 08 09 0A 0B 0C 0D 0E 0F
--------------------------------------------------------------------------
super block / 000000 08 00 01 00 10 00 08 00 04 00 04 00 FA 00 00 00 ................
\ 000010 00 00 00 00 00 00 00 00 56 46 53 2D 33 00 00 00 ........VFS-3...
/ 000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
dir. entries | 000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
| 000040 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
\ 000050 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
FAT | 000060 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
/ 000070 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
| 000080 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
| 000090 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
| 0000A0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
data area | 0000B0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
| 0000C0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
| 0000D0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
\ 0000E0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
|
Total sectors: 8
Sectors per cluster: 1
Bytes per sector: 16
Available sectors: 8
Directory entries: 4
Available direntries: 4
Filesystem type: FA
Reserved: 00 00 00 00 00 00 00 00 00 00 00
Label: 'VFS-3'
Comments:
When a "real" filesystem is created there is no guarantee
that all of the data blocks have been initialized to 0.
What will likely happen is that the values will be whatever
random garbage happens to be on the disk at that
location when the filesystem was created. The directory
area and file allocation table (FAT) will likely be
initialized to 0.
|
Note: Since our filesystem is so small and basic, it only takes a few lines of code (and a fraction of a second) to create an empty filesystem. More complex filesystems can take much longer to create as they must construct much more sophisticated data structures to manage billions and trillions (and more!) of bytes of data. Remember this?
Creating Files
Here are 4 small files that we'll use to demonstrate. We'll look at the entire filesystem after each one has been stored. Each line ends with an invisible newline (<NL>). The number in the name of the file reflects how many characters are in the file.This is the configuration of the filesystem:
file9.txt file16.txt file23.txt file61.txt
Given this configuration (i.e. 16 bytes per sector) and the size of each file above, we know that:
Attribute Value total_sectors 8 sectors_per_cluster 1 bytes_per_sectors 16 total_direntries 4
Note: As you can imagine, the larger the sector (bytes per sector), the more wasted bytes you are likely to have. On the other hand, smaller sectors lead to many small blocks which require a lot more overhead to manage and therefore will have a negative impact on performance. On average, each file in the filesystem will waste 1/2 of a block. As always in computer science, it's a trade-off.
Note: Since all files require at least one block, even a file that is a single byte will require an entire block to store. More than 99% of the bytes in the block will be wasted.
| Raw filesystem dump (240 bytes) | Super block information (32 bytes) | |
|---|---|---|
00 01 02 03 04 05 06 07 08 09 0A 0B 0C 0D 0E 0F
--------------------------------------------------------------------------
super block / 000000 08 00 01 00 10 00 07 00 04 00 03 00 FA 00 00 00 ................
\ 000010 00 00 00 00 00 00 00 00 56 46 53 2D 33 00 00 00 ........VFS-3...
/ 000020 66 69 6C 65 39 2E 74 78 74 00 00 00 09 00 00 00 file9.txt.......
dir. entries | 000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
| 000040 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
\ 000050 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
FAT | 000060 FF FF 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
/ 000070 39 20 63 68 61 72 73 2E 0A 00 00 00 00 00 00 00 9 chars.........
| 000080 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
| 000090 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
| 0000A0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
data area | 0000B0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
| 0000C0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
| 0000D0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
\ 0000E0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
|
Total sectors: 8
Sectors per cluster: 1
Bytes per sector: 16
Available sectors: 7
Directory entries: 4
Available direntries: 3
Filesystem type: FA
Reserved: 00 00 00 00 00 00 00 00 00 00 00
Label: 'VFS-3'
Comments:
Each new file will decrement the value of Available
direntries. Each block that is consumed by a new
file will decrement the value of Available sectors.
|
When creating a new file, all four sections will require some modifications:
Showing the empty filesystem with the updated one.
| Raw filesystem dump (240 bytes) | Super block information (32 bytes) | |
|---|---|---|
00 01 02 03 04 05 06 07 08 09 0A 0B 0C 0D 0E 0F
--------------------------------------------------------------------------
super block / 000000 08 00 01 00 10 00 06 00 04 00 02 00 FA 00 00 00 ................
\ 000010 00 00 00 00 00 00 00 00 56 46 53 2D 33 00 00 00 ........VFS-3...
/ 000020 66 69 6C 65 39 2E 74 78 74 00 00 00 09 00 00 00 file9.txt.......
dir. entries | 000030 66 69 6C 65 31 36 2E 74 78 74 01 00 10 00 00 00 file16.txt......
| 000040 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
\ 000050 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
FAT | 000060 FF FF FF FF 00 00 00 00 00 00 00 00 00 00 00 00 ................
/ 000070 39 20 63 68 61 72 73 2E 0A 00 00 00 00 00 00 00 9 chars.........
| 000080 31 36 20 63 68 61 72 61 63 74 65 72 73 2E 2E 0A 16 characters...
| 000090 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
| 0000A0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
data area | 0000B0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
| 0000C0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
| 0000D0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
\ 0000E0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
|
Total sectors: 8
Sectors per cluster: 1
Bytes per sector: 16
Available sectors: 6
Directory entries: 4
Available direntries: 2
Filesystem type: FA
Reserved: 00 00 00 00 00 00 00 00 00 00 00
Label: 'VFS-3'
Comments:
Files can't "share" data blocks, so the "extra" space
in the last block of file9.txt is wasted and
can't be used for any other file.
|
| Raw filesystem dump (240 bytes) | Super block information (32 bytes) | |
|---|---|---|
00 01 02 03 04 05 06 07 08 09 0A 0B 0C 0D 0E 0F
--------------------------------------------------------------------------
super block / 000000 08 00 01 00 10 00 04 00 04 00 01 00 FA 00 00 00 ................
\ 000010 00 00 00 00 00 00 00 00 56 46 53 2D 33 00 00 00 ........VFS-3...
/ 000020 66 69 6C 65 39 2E 74 78 74 00 00 00 09 00 00 00 file9.txt.......
dir. entries | 000030 66 69 6C 65 31 36 2E 74 78 74 01 00 10 00 00 00 file16.txt......
| 000040 66 69 6C 65 32 33 2E 74 78 74 02 00 17 00 00 00 file23.txt......
\ 000050 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
FAT | 000060 FF FF FF FF 03 00 FF FF 00 00 00 00 00 00 00 00 ................
/ 000070 39 20 63 68 61 72 73 2E 0A 00 00 00 00 00 00 00 9 chars.........
| 000080 31 36 20 63 68 61 72 61 63 74 65 72 73 2E 2E 0A 16 characters...
| 000090 45 78 61 63 74 6C 79 20 32 33 20 63 68 61 72 61 Exactly 23 chara
| 0000A0 63 74 65 72 73 2E 0A 00 00 00 00 00 00 00 00 00 cters...........
data area | 0000B0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
| 0000C0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
| 0000D0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
\ 0000E0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
|
Total sectors: 8
Sectors per cluster: 1
Bytes per sector: 16
Available sectors: 4
Directory entries: 4
Available direntries: 1
Filesystem type: FA
Reserved: 00 00 00 00 00 00 00 00 00 00 00
Label: 'VFS-3'
Comments:
At this point, there are 3 files in the system and
they consume 4 data blocks. There is one directory
entry and 64 data blocks remaining. The filesystem
will be considered full when we run out of either
directory entries or data blocks, whichever runs out
first.
|
| Raw filesystem dump (240 bytes) | Super block information (32 bytes) | |
|---|---|---|
00 01 02 03 04 05 06 07 08 09 0A 0B 0C 0D 0E 0F
--------------------------------------------------------------------------
super block / 000000 08 00 01 00 10 00 00 00 04 00 00 00 FA 00 00 00 ................
\ 000010 00 00 00 00 00 00 00 00 56 46 53 2D 33 00 00 00 ........VFS-3...
/ 000020 66 69 6C 65 39 2E 74 78 74 00 00 00 09 00 00 00 file9.txt.......
dir. entries | 000030 66 69 6C 65 31 36 2E 74 78 74 01 00 10 00 00 00 file16.txt......
| 000040 66 69 6C 65 32 33 2E 74 78 74 02 00 17 00 00 00 file23.txt......
\ 000050 66 69 6C 65 36 31 2E 74 78 74 04 00 3D 00 00 00 file61.txt..=...
FAT | 000060 FF FF FF FF 03 00 FF FF 05 00 06 00 07 00 FF FF ................
/ 000070 39 20 63 68 61 72 73 2E 0A 00 00 00 00 00 00 00 9 chars.........
| 000080 31 36 20 63 68 61 72 61 63 74 65 72 73 2E 2E 0A 16 characters...
| 000090 45 78 61 63 74 6C 79 20 32 33 20 63 68 61 72 61 Exactly 23 chara
| 0000A0 63 74 65 72 73 2E 0A 00 00 00 00 00 00 00 00 00 cters...........
data area | 0000B0 52 6F 73 65 73 20 61 72 65 20 72 65 64 2E 20 56 Roses are red. V
| 0000C0 69 6F 6C 65 74 73 20 61 72 65 20 62 6C 75 65 2E iolets are blue.
| 0000D0 0A 54 68 69 73 20 74 65 78 74 20 69 73 20 36 31 .This text is 61
\ 0000E0 20 63 68 61 72 73 20 6C 6F 6E 67 2E 0A 00 00 00 chars long.....
|
Total sectors: 8
Sectors per cluster: 1
Bytes per sector: 16
Available sectors: 0
Directory entries: 4
Available direntries: 0
Filesystem type: FA
Reserved: 00 00 00 00 00 00 00 00 00 00 00
Label: 'VFS-3'
Comments:
The filesystem is now full. No directory entries and no
data blocks are available.
|
The filesystem is now full. There are no more directory entries available and there are no more data blocks. Any attempt to create another file will result in an error from the filesystem with a message along the lines of "No space left on device."
It turns out that with this example we ran out of directory entries at the same time we ran out of data blocks. This is an unlikely situation. Usually, we either run out of directory entries while still having free data blocks, or, we run out of data blocks while still having free directory entries.
After creating file9a.txt:
| Raw filesystem dump (240 bytes) | Super block information (32 bytes) | |
|---|---|---|
00 01 02 03 04 05 06 07 08 09 0A 0B 0C 0D 0E 0F
--------------------------------------------------------------------------
super block / 000000 08 00 01 00 10 00 03 00 04 00 00 00 FA 00 00 00 ................
\ 000010 00 00 00 00 00 00 00 00 56 46 53 2D 33 00 00 00 ........VFS-3...
/ 000020 66 69 6C 65 39 2E 74 78 74 00 00 00 09 00 00 00 file9.txt.......
dir. entries | 000030 66 69 6C 65 31 36 2E 74 78 74 01 00 10 00 00 00 file16.txt......
| 000040 66 69 6C 65 32 33 2E 74 78 74 02 00 17 00 00 00 file23.txt......
\ 000050 66 69 6C 65 39 61 2E 74 78 74 04 00 09 00 00 00 file9a.txt......
FAT | 000060 FF FF FF FF 03 00 FF FF FF FF 00 00 00 00 00 00 ................
/ 000070 39 20 63 68 61 72 73 2E 0A 00 00 00 00 00 00 00 9 chars.........
| 000080 31 36 20 63 68 61 72 61 63 74 65 72 73 2E 2E 0A 16 characters...
| 000090 45 78 61 63 74 6C 79 20 32 33 20 63 68 61 72 61 Exactly 23 chara
| 0000A0 63 74 65 72 73 2E 0A 00 00 00 00 00 00 00 00 00 cters...........
data area | 0000B0 39 20 63 68 61 72 73 2E 0A 00 00 00 00 00 00 00 9 chars.........
| 0000C0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
| 0000D0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
\ 0000E0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
|
Total sectors: 8
Sectors per cluster: 1
Bytes per sector: 16
Available sectors: 3
Directory entries: 4
Available direntries: 0
Filesystem type: FA
Reserved: 00 00 00 00 00 00 00 00 00 00 00
Label: 'VFS-3'
Comments:
The filesystem is still full, even though there are 3
data blocks available. Because there are no more
directory entries available, no new files can be added
to the filesystem. This is not uncommon when a
filesystem has many small files.
|
The filesystem is still technically full, even though there are 3 data blocks available. But, with no more directory entries available, you can't create a new file. Existing files can grow because they already have a directory entry and there are free data blocks, but no new files can be created.
This file is 69 bytes in size, but there are only 64 bytes (4 * 16) left in the filesystem. This is what the result will be when attempting to store the whole file:Roses are red.<NL> Violets are blue.<NL> Some poems rhyme.<NL> But not this one.<NL>
After creating poem.txt:
| Raw filesystem dump (240 bytes) | Super block information (32 bytes) | |
|---|---|---|
00 01 02 03 04 05 06 07 08 09 0A 0B 0C 0D 0E 0F
--------------------------------------------------------------------------
super block / 000000 08 00 01 00 10 00 00 00 04 00 00 00 FA 00 00 00 ................
\ 000010 00 00 00 00 00 00 00 00 56 46 53 2D 33 00 00 00 ........VFS-3...
/ 000020 66 69 6C 65 39 2E 74 78 74 00 00 00 09 00 00 00 file9.txt.......
dir. entries | 000030 66 69 6C 65 31 36 2E 74 78 74 01 00 10 00 00 00 file16.txt......
| 000040 66 69 6C 65 32 33 2E 74 78 74 02 00 17 00 00 00 file23.txt......
\ 000050 70 6F 65 6D 2E 74 78 74 00 00 04 00 40 00 00 00 poem.txt....@...
FAT | 000060 FF FF FF FF 03 00 FF FF 05 00 06 00 07 00 FF FF ................
/ 000070 39 20 63 68 61 72 73 2E 0A 00 00 00 00 00 00 00 9 chars.........
| 000080 31 36 20 63 68 61 72 61 63 74 65 72 73 2E 2E 0A 16 characters...
| 000090 45 78 61 63 74 6C 79 20 32 33 20 63 68 61 72 61 Exactly 23 chara
| 0000A0 63 74 65 72 73 2E 0A 00 00 00 00 00 00 00 00 00 cters...........
data area | 0000B0 52 6F 73 65 73 20 61 72 65 20 72 65 64 2E 0A 56 Roses are red..V
| 0000C0 69 6F 6C 65 74 73 20 61 72 65 20 62 6C 75 65 2E iolets are blue.
| 0000D0 0A 53 6F 6D 65 20 70 6F 65 6D 73 20 72 68 79 6D .Some poems rhym
\ 0000E0 65 2E 0A 42 75 74 20 6E 6F 74 20 74 68 69 73 20 e..But not this
|
Total sectors: 8
Sectors per cluster: 1
Bytes per sector: 16
Available sectors: 0
Directory entries: 4
Available direntries: 0
Filesystem type: FA
Reserved: 00 00 00 00 00 00 00 00 00 00 00
Label: 'VFS-3'
Comments:
The last file was truncated because the filesystem ran
out of data blocks. A truncated file will always have
a size that is exactly a multiple of the bytes per
sector.
|
You'll notice that the last file was truncated. Only the bytes that could fit were stored. The size of the file in the filesystem is also modified to reflect this fact. A message would also be displayed saying something along the lines of "No space left on device."
When in the Course of human events, it becomes necessary for one people to dissolve the political bands which have connected them with another, and to assume among the powers of the earth, the separate and equal station to which the Laws of Nature and of Nature's God entitle them, a decent respect to the opinions of mankind requires that they should declare the causes which impel them to the separation.<NL>
After creating preamble:
| Raw filesystem dump (240 bytes) | Super block information (32 bytes) | |
|---|---|---|
00 01 02 03 04 05 06 07 08 09 0A 0B 0C 0D 0E 0F
--------------------------------------------------------------------------
super block / 000000 08 00 01 00 10 00 00 00 04 00 03 00 FA 00 00 00 ................
\ 000010 00 00 00 00 00 00 00 00 56 46 53 2D 33 00 00 00 ........VFS-3...
/ 000020 70 72 65 61 6D 62 6C 65 00 00 00 00 80 00 00 00 preamble........
dir. entries | 000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
| 000040 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
\ 000050 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
FAT | 000060 01 00 02 00 03 00 04 00 05 00 06 00 07 00 FF FF ................
/ 000070 57 68 65 6E 20 69 6E 20 74 68 65 20 43 6F 75 72 When in the Cour
| 000080 73 65 20 6F 66 20 68 75 6D 61 6E 20 65 76 65 6E se of human even
| 000090 74 73 2C 20 69 74 20 62 65 63 6F 6D 65 73 20 6E ts, it becomes n
| 0000A0 65 63 65 73 73 61 72 79 20 66 6F 72 20 6F 6E 65 ecessary for one
data area | 0000B0 20 70 65 6F 70 6C 65 20 74 6F 20 64 69 73 73 6F people to disso
| 0000C0 6C 76 65 20 74 68 65 20 70 6F 6C 69 74 69 63 61 lve the politica
| 0000D0 6C 20 62 61 6E 64 73 20 77 68 69 63 68 20 68 61 l bands which ha
\ 0000E0 76 65 20 63 6F 6E 6E 65 63 74 65 64 20 74 68 65 ve connected the
|
Total sectors: 8
Sectors per cluster: 1
Bytes per sector: 16
Available sectors: 0
Directory entries: 4
Available direntries: 3
Filesystem type: FA
Reserved: 00 00 00 00 00 00 00 00 00 00 00
Label: 'VFS-3'
Comments:
There is only one file in this filesystem, but the
filesystem is full. There are directory entries
available, but there are no data blocks available. No
new files can be created.
|
Like before, you'll notice that the last file was truncated. Only the bytes that could fit were stored. The size of the file in the filesystem is also modified to reflect this fact. A message would also be displayed saying something along the lines of "No space left on device." All of the data blocks have been consumed, yet we only have one file in the filesystem. This can happen if you have very large files.
Deleting Files
It turns out that deleting files requires much less work than creating them. This is because a file's data blocks are not deleted, per se. They are simply marked as deleted, which means that they can be re-used by other files in the future. We'll start with the full filesystem from above, delete each file, and see what the filesystem looks like after each step.The full filesystem:
So what does it mean to "delete" a file? Deleting a file simply means changing the first character of the filename (in the directory entry) to a special character. That special character will be the question mark ? character. Then, we will set all of the file's FAT entries to 0. The data blocks will be left intact. BTW, the ? character is an illegal character in a filename (in our system, as well as others), which means it won't conflict with real file names.
Raw filesystem dump (240 bytes) Super block information (32 bytes) 00 01 02 03 04 05 06 07 08 09 0A 0B 0C 0D 0E 0F -------------------------------------------------------------------------- super block / 000000 08 00 01 00 10 00 00 00 04 00 00 00 FA 00 00 00 ................ \ 000010 00 00 00 00 00 00 00 00 56 46 53 2D 33 00 00 00 ........VFS-3... / 000020 66 69 6C 65 39 2E 74 78 74 00 00 00 09 00 00 00 file9.txt....... dir. entries | 000030 66 69 6C 65 31 36 2E 74 78 74 01 00 10 00 00 00 file16.txt...... | 000040 66 69 6C 65 32 33 2E 74 78 74 02 00 17 00 00 00 file23.txt...... \ 000050 66 69 6C 65 36 31 2E 74 78 74 04 00 3D 00 00 00 file61.txt..=... FAT | 000060 FF FF FF FF 03 00 FF FF 05 00 06 00 07 00 FF FF ................ / 000070 39 20 63 68 61 72 73 2E 0A 00 00 00 00 00 00 00 9 chars......... | 000080 31 36 20 63 68 61 72 61 63 74 65 72 73 2E 2E 0A 16 characters... | 000090 45 78 61 63 74 6C 79 20 32 33 20 63 68 61 72 61 Exactly 23 chara | 0000A0 63 74 65 72 73 2E 0A 00 00 00 00 00 00 00 00 00 cters........... data area | 0000B0 52 6F 73 65 73 20 61 72 65 20 72 65 64 2E 20 56 Roses are red. V | 0000C0 69 6F 6C 65 74 73 20 61 72 65 20 62 6C 75 65 2E iolets are blue. | 0000D0 0A 54 68 69 73 20 74 65 78 74 20 69 73 20 36 31 .This text is 61 \ 0000E0 20 63 68 61 72 73 20 6C 6F 6E 67 2E 0A 00 00 00 chars long.....Total sectors: 8 Sectors per cluster: 1 Bytes per sector: 16 Available sectors: 0 Directory entries: 4 Available direntries: 0 Filesystem type: FA Reserved: 00 00 00 00 00 00 00 00 00 00 00 Label: 'VFS-3'
This is the algorithm to delete a file in your system:
The bytes that are highlighted above are the ones that were modified when the file was deleted. Notice that the data blocks are still intact. The super block has also been updated to reflect the new state of the filesystem.
Raw filesystem dump (240 bytes) Super block information (32 bytes) 00 01 02 03 04 05 06 07 08 09 0A 0B 0C 0D 0E 0F -------------------------------------------------------------------------- super block / 000000 08 00 01 00 10 00 02 00 04 00 01 00 FA 00 00 00 ................ \ 000010 00 00 00 00 00 00 00 00 56 46 53 2D 33 00 00 00 ........VFS-3... / 000020 66 69 6C 65 39 2E 74 78 74 00 00 00 09 00 00 00 file9.txt....... dir. entries | 000030 66 69 6C 65 31 36 2E 74 78 74 01 00 10 00 00 00 file16.txt...... | 000040 3F 69 6C 65 32 33 2E 74 78 74 02 00 17 00 00 00 ?ile23.txt...... \ 000050 66 69 6C 65 36 31 2E 74 78 74 04 00 3D 00 00 00 file61.txt..=... FAT | 000060 FF FF FF FF 00 00 00 00 05 00 06 00 07 00 FF FF ................ / 000070 39 20 63 68 61 72 73 2E 0A 00 00 00 00 00 00 00 9 chars......... | 000080 31 36 20 63 68 61 72 61 63 74 65 72 73 2E 2E 0A 16 characters... | 000090 45 78 61 63 74 6C 79 20 32 33 20 63 68 61 72 61 Exactly 23 chara | 0000A0 63 74 65 72 73 2E 0A 00 00 00 00 00 00 00 00 00 cters........... data area | 0000B0 52 6F 73 65 73 20 61 72 65 20 72 65 64 2E 20 56 Roses are red. V | 0000C0 69 6F 6C 65 74 73 20 61 72 65 20 62 6C 75 65 2E iolets are blue. | 0000D0 0A 54 68 69 73 20 74 65 78 74 20 69 73 20 36 31 .This text is 61 \ 0000E0 20 63 68 61 72 73 20 6C 6F 6E 67 2E 0A 00 00 00 chars long.....Total sectors: 8 Sectors per cluster: 1 Bytes per sector: 16 Available sectors: 2 Directory entries: 4 Available direntries: 1 Filesystem type: FA Reserved: 00 00 00 00 00 00 00 00 00 00 00 Label: 'VFS-3'
Note: The fact that the data blocks are left untouched is what allows special utility programs to undelete files that have been deleted. As long as the data blocks do not get re-used, it is possible to recover the data from a deleted file. Some filesystems make this undeletion easier or harder than others. There are also special tools that will perform a secure erase, which means that all of the data blocks are overwritten with zeros or random garbage to prevent any attempt at recovering the data.
This is what the filesystem looks like after deleting (in any order) the remaining files:
At this point, the filesystem is empty and 4 new files can be created. When the new files are created, the data blocks will get re-used and the old data will get overwritten. That's what we'll look at next.
Raw filesystem dump (240 bytes) Super block information (32 bytes) 00 01 02 03 04 05 06 07 08 09 0A 0B 0C 0D 0E 0F -------------------------------------------------------------------------- super block / 000000 08 00 01 00 10 00 08 00 04 00 04 00 FA 00 00 00 ................ \ 000010 00 00 00 00 00 00 00 00 56 46 53 2D 33 00 00 00 ........VFS-3... / 000020 3F 69 6C 65 39 2E 74 78 74 00 00 00 09 00 00 00 ?ile9.txt....... dir. entries | 000030 3F 69 6C 65 31 36 2E 74 78 74 01 00 10 00 00 00 ?ile16.txt...... | 000040 3F 69 6C 65 32 33 2E 74 78 74 02 00 17 00 00 00 ?ile23.txt...... \ 000050 3F 69 6C 65 36 31 2E 74 78 74 04 00 3D 00 00 00 ?ile61.txt..=... FAT | 000060 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................ / 000070 39 20 63 68 61 72 73 2E 0A 00 00 00 00 00 00 00 9 chars......... | 000080 31 36 20 63 68 61 72 61 63 74 65 72 73 2E 2E 0A 16 characters... | 000090 45 78 61 63 74 6C 79 20 32 33 20 63 68 61 72 61 Exactly 23 chara | 0000A0 63 74 65 72 73 2E 0A 00 00 00 00 00 00 00 00 00 cters........... data area | 0000B0 52 6F 73 65 73 20 61 72 65 20 72 65 64 2E 20 56 Roses are red. V | 0000C0 69 6F 6C 65 74 73 20 61 72 65 20 62 6C 75 65 2E iolets are blue. | 0000D0 0A 54 68 69 73 20 74 65 78 74 20 69 73 20 36 31 .This text is 61 \ 0000E0 20 63 68 61 72 73 20 6C 6F 6E 67 2E 0A 00 00 00 chars long.....Total sectors: 8 Sectors per cluster: 1 Bytes per sector: 16 Available sectors: 8 Directory entries: 4 Available direntries: 4 Filesystem type: FA Reserved: 00 00 00 00 00 00 00 00 00 00 00 Label: 'VFS-3'
Creating/Deleting/Creating = Fragmentation
Up until now, we haven't re-used any data blocks. We either created new files with previously unused data blocks or deleted (marked) files. If we never created another file once we started deleting files, life would be simple. Now, however, we are going to start to develop "holes" in the filesystem when we delete files that are in-between other files. Examples will clarify.When we want to create a new file, how do we know which blocks to use? This simple filesystem uses a very simple and straight-forward technique: The first block that is available (as determined by the file allocation table) will be the first block for our new file. If the file requires multiple blocks, we will continue searching forward in a linear fashion looking for free blocks in the FAT.
Example: Suppose we have a full filesystem with 8 small files. (Yes, it's unrealistic.) Each file fits into a single block. Assume there are only 8 data blocks and each block is 512 bytes. There are also only 8 directory entries. The data area would look something like this:
Graphically, the filesystem would look something like this:
If we were to delete files FileB, FileD, FileF, and FileH, we'd have this:
and the filesystem would look something like this:
Observations:
Now, suppose we have a bunch of data that we want to save to a file called FileZ. The data contains 2048 bytes and requires 4 blocks:
We don't have 2,048 contiguous bytes (4 contiguous blocks) so we are going to have to split up the data into 4 blocks that will look something like this:
This is what the filesystem looks like after adding the file:
You can clearly see that FileZ is fragmented. However, this is a much better outcome than just saying that the disk is full and wasting all of the available blocks.
In a nutshell, this is how file fragmentation happens. Let's see how this will be handled with our simple filesystem.Self-check: Make sure that you can explain what each value in all of the diagrams represents. This will let you know if you understand how this works.
First, let's create a filesystem with several small files. (Deleting small files and then creating a large file is generally how fragmentation happens.) This is the configuration of the file system.
And here is a full filesystem (shown in sections) with 8 files.
Attribute Value total_sectors 8 sectors_per_cluster 1 bytes_per_sectors 16 total_direntries 8
There are 8 files that are all 16 bytes in size. This means they each consume exactly one full data block. The contents match the name of the files. This is so you can easily see where one file stops and the next file begins. You'll also be able to easily see the fragmented files because they won't be contiguous.
Raw filesystem dump (304 bytes) Super block information (32 bytes) 00 01 02 03 04 05 06 07 08 09 0A 0B 0C 0D 0E 0F -------------------------------------------------------------------------- 000000 08 00 01 00 10 00 00 00 08 00 00 00 FA 00 00 00 ................ 000010 00 00 00 00 00 00 00 00 56 46 53 2D 33 00 00 00 ........VFS-3... 000020 46 69 6C 65 41 00 00 00 00 00 00 00 10 00 00 00 FileA........... 000030 46 69 6C 65 42 00 00 00 00 00 01 00 10 00 00 00 FileB........... 000040 46 69 6C 65 43 00 00 00 00 00 02 00 10 00 00 00 FileC........... 000050 46 69 6C 65 44 00 00 00 00 00 03 00 10 00 00 00 FileD........... 000060 46 69 6C 65 45 00 00 00 00 00 04 00 10 00 00 00 FileE........... 000070 46 69 6C 65 46 00 00 00 00 00 05 00 10 00 00 00 FileF........... 000080 46 69 6C 65 47 00 00 00 00 00 06 00 10 00 00 00 FileG........... 000090 46 69 6C 65 48 00 00 00 00 00 07 00 10 00 00 00 FileH........... 0000A0 FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF ................ 0000B0 41 41 41 41 41 41 41 41 41 41 41 41 41 41 41 41 AAAAAAAAAAAAAAAA 0000C0 42 42 42 42 42 42 42 42 42 42 42 42 42 42 42 42 BBBBBBBBBBBBBBBB 0000D0 43 43 43 43 43 43 43 43 43 43 43 43 43 43 43 43 CCCCCCCCCCCCCCCC 0000E0 44 44 44 44 44 44 44 44 44 44 44 44 44 44 44 44 DDDDDDDDDDDDDDDD 0000F0 45 45 45 45 45 45 45 45 45 45 45 45 45 45 45 45 EEEEEEEEEEEEEEEE 000100 46 46 46 46 46 46 46 46 46 46 46 46 46 46 46 46 FFFFFFFFFFFFFFFF 000110 47 47 47 47 47 47 47 47 47 47 47 47 47 47 47 47 GGGGGGGGGGGGGGGG 000120 48 48 48 48 48 48 48 48 48 48 48 48 48 48 48 48 HHHHHHHHHHHHHHHHTotal sectors: 8 Sectors per cluster: 1 Bytes per sector: 16 Available sectors: 0 Directory entries: 8 Available direntries: 0 Filesystem type: FA Reserved: 00 00 00 00 00 00 00 00 00 00 00 Label: 'VFS-3'
Self-check: At this point, you should be able to explain what every byte in the output above means. That will let you know if you understand what's been going on here.
Ok, so let's delete 4 files: FileB, FileD, FileF, FileH. This will leave us with 4 data blocks, none of which are contiguous, meaning, they are fragmented:
Now, we create a new file that is 64 bytes in size called FileZ:
Raw filesystem dump (304 bytes) Super block information (32 bytes) 00 01 02 03 04 05 06 07 08 09 0A 0B 0C 0D 0E 0F -------------------------------------------------------------------------- 000000 08 00 01 00 10 00 04 00 08 00 04 00 FA 00 00 00 ................ 000010 00 00 00 00 00 00 00 00 56 46 53 2D 33 00 00 00 ........VFS-3... 000020 46 69 6C 65 41 00 00 00 00 00 00 00 10 00 00 00 FileA........... 000030 3F 69 6C 65 42 00 00 00 00 00 01 00 10 00 00 00 ?ileB........... 000040 46 69 6C 65 43 00 00 00 00 00 02 00 10 00 00 00 FileC........... 000050 3F 69 6C 65 44 00 00 00 00 00 03 00 10 00 00 00 ?ileD........... 000060 46 69 6C 65 45 00 00 00 00 00 04 00 10 00 00 00 FileE........... 000070 3F 69 6C 65 46 00 00 00 00 00 05 00 10 00 00 00 ?ileF........... 000080 46 69 6C 65 47 00 00 00 00 00 06 00 10 00 00 00 FileG........... 000090 3F 69 6C 65 48 00 00 00 00 00 07 00 10 00 00 00 ?ileH........... 0000A0 FF FF 00 00 FF FF 00 00 FF FF 00 00 FF FF 00 00 ................ 0000B0 41 41 41 41 41 41 41 41 41 41 41 41 41 41 41 41 AAAAAAAAAAAAAAAA 0000C0 42 42 42 42 42 42 42 42 42 42 42 42 42 42 42 42 BBBBBBBBBBBBBBBB 0000D0 43 43 43 43 43 43 43 43 43 43 43 43 43 43 43 43 CCCCCCCCCCCCCCCC 0000E0 44 44 44 44 44 44 44 44 44 44 44 44 44 44 44 44 DDDDDDDDDDDDDDDD 0000F0 45 45 45 45 45 45 45 45 45 45 45 45 45 45 45 45 EEEEEEEEEEEEEEEE 000100 46 46 46 46 46 46 46 46 46 46 46 46 46 46 46 46 FFFFFFFFFFFFFFFF 000110 47 47 47 47 47 47 47 47 47 47 47 47 47 47 47 47 GGGGGGGGGGGGGGGG 000120 48 48 48 48 48 48 48 48 48 48 48 48 48 48 48 48 HHHHHHHHHHHHHHHHTotal sectors: 8 Sectors per cluster: 1 Bytes per sector: 16 Available sectors: 4 Directory entries: 8 Available direntries: 4 Filesystem type: FA Reserved: 00 00 00 00 00 00 00 00 00 00 00 Label: 'VFS-3'
It's clear that FileZ has been fragmented into 4 non-contiguous blocks. Again, this is more desirable than simply truncating the file or not storing any of it at all. This was a conscious design decision that the inventors of the FAT-like filesystem (and most others, too) made.
Raw filesystem dump (304 bytes) Super block information (32 bytes) 00 01 02 03 04 05 06 07 08 09 0A 0B 0C 0D 0E 0F -------------------------------------------------------------------------- 000000 08 00 01 00 10 00 00 00 08 00 03 00 FA 00 00 00 ................ 000010 00 00 00 00 00 00 00 00 56 46 53 2D 33 00 00 00 ........VFS-3... 000020 46 69 6C 65 41 00 00 00 00 00 00 00 10 00 00 00 FileA........... 000030 46 69 6C 65 5A 00 00 00 00 00 01 00 40 00 00 00 FileZ.......@... 000040 46 69 6C 65 43 00 00 00 00 00 02 00 10 00 00 00 FileC........... 000050 3F 69 6C 65 44 00 00 00 00 00 03 00 10 00 00 00 ?ileD........... 000060 46 69 6C 65 45 00 00 00 00 00 04 00 10 00 00 00 FileE........... 000070 3F 69 6C 65 46 00 00 00 00 00 05 00 10 00 00 00 ?ileF........... 000080 46 69 6C 65 47 00 00 00 00 00 06 00 10 00 00 00 FileG........... 000090 3F 69 6C 65 48 00 00 00 00 00 07 00 10 00 00 00 ?ileH........... 0000A0 FF FF 03 00 FF FF 05 00 FF FF 07 00 FF FF FF FF ................ 0000B0 41 41 41 41 41 41 41 41 41 41 41 41 41 41 41 41 AAAAAAAAAAAAAAAA 0000C0 5A 5A 5A 5A 5A 5A 5A 5A 5A 5A 5A 5A 5A 5A 5A 5A ZZZZZZZZZZZZZZZZ 0000D0 43 43 43 43 43 43 43 43 43 43 43 43 43 43 43 43 CCCCCCCCCCCCCCCC 0000E0 5A 5A 5A 5A 5A 5A 5A 5A 5A 5A 5A 5A 5A 5A 5A 5A ZZZZZZZZZZZZZZZZ 0000F0 45 45 45 45 45 45 45 45 45 45 45 45 45 45 45 45 EEEEEEEEEEEEEEEE 000100 5A 5A 5A 5A 5A 5A 5A 5A 5A 5A 5A 5A 5A 5A 5A 5A ZZZZZZZZZZZZZZZZ 000110 47 47 47 47 47 47 47 47 47 47 47 47 47 47 47 47 GGGGGGGGGGGGGGGG 000120 5A 5A 5A 5A 5A 5A 5A 5A 5A 5A 5A 5A 5A 5A 5A 5A ZZZZZZZZZZZZZZZZTotal sectors: 8 Sectors per cluster: 1 Bytes per sector: 16 Available sectors: 0 Directory entries: 8 Available direntries: 3 Filesystem type: FA Reserved: 00 00 00 00 00 00 00 00 00 00 00 Label: 'VFS-3'
Some Implementation Details
To make the implementation easier, you should have pointers to each of the four sections in the filesystem.

Notes: (The diagram is not to scale.)
typedef struct SuperBlock
{
unsigned short total_sectors; // Total number of sectors
unsigned short sectors_per_cluster; // Number of sectors in each cluster
unsigned short bytes_per_sector; // Number of bytes in each sector
unsigned short available_sectors; // Number of sectors available
unsigned short total_direntries; // Total number of directory entries
unsigned short available_direntries; // Number of available dir entries
unsigned char fs_type; // File system type (FA for SFAT)
unsigned char reserved[11]; // Reserved, all set to 0
unsigned char label[8]; // Not guaranteed to be NUL-terminated
}SuperBlock;
typedef struct DirEntry
{
unsigned char name[10]; // Not guaranteed to be NUL-terminated
unsigned short fat_entry; // First data block
unsigned int size; // Size of the file in bytes
}DirEntry;
Calculating the pointers is simple pointer arithmetic. Remember, the entire filesystem is just an array of unsigned characters (bytes). How they are interpreted depends on which section you are referring to. The pointers are all offsets from the beginning of the array and their types match what they are pointing at.
sizeof(struct SuperBlock)
sizeof(struct SuperBlock)) + number_of_direntries * sizeof(struct DirEntry)
sizeof(struct SuperBlock)) + number_of_direntries * sizeof(struct DirEntry) + total_sectors * sizeof(unsigned short)
Now, if you wanted to access any member in the superblock:struct SuperBlock *superblock_ptr; struct DirEntry *direntries_ptr; unsigned short *fat_ptr; unsigned char *data_blocks_ptr;
To move to the next directory entry, fat entry, or data block, you could do something like this:superblock_ptr->member;
Or you could use random access with subscripting for the directory entries and FAT:direntries_ptr++; /* Move to next directory entry */ fat_ptr++; /* Move to next FAT entry */ data_blocks_ptr += bytes_per_sector; /* Move to next data block */
Since the entire filesystem is an array of unsigned characters, you will need to do some casting to get the other pointer types to work properly. This is expected, especially with low-level code such as a filesystem. (Memory is similar in that it's just an array of characters.)direntries_ptr[3]; /* 4th directory entry */ fat_ptr[8]; /* 9th fat entry */
Once you have these pointers set up properly, moving through the various sections of the filesystem to locate objects is trivial and very efficient.
Self-check:
1. Suppose you want to support filenames up to 255 bytes in length. What changes would
you have to make? What are the pros and cons of that?
2. Suppose you wanted to support millions of files. What changes would you need to make?
3. Suppose you wanted to handle files that were GBs in size. What changes would you need to make?
4. Supposed you wanted to keep track of a files last modification time/data and owner.
What changes would need to be made?
5. Currently, we can only create new files. If you wanted to be able to append to
an existing file, how would you go about that?
Why The File Allocation Table?
In essence, the scheme that we're using here is based on a singly-linked list. The difference is that we are storing each next pointer of a "node" (block) in a separate array, instead of in the node/block itself. Why is that? In a word: Performance.The speed of memory is measured in nanoseconds (1 billionth of a second) and the speed of disks (HDD or SSD) is measured in milliseconds (1 thousandth of a second). That makes memory 1,000,000 times faster than the disk. Or, another way to say it is that the disk is 1,000,000 times slower than memory. There is overhead in accessing memory, so to compensate we'll just say that memory access takes microseconds (1 millionth of a second), so the disk is only 1,000 times slower (and that's being generous.)
Bottom line: We want to avoid accessing the disk unless we absolutely, positively must.
Linked lists are used everywhere in programming, but they are usually all in memory. For example, the list below shows 5 blocks of data (nodes) stored in memory. Each node has a next pointer that points to the location of the next node. We can assume that each block contains a few thousand bytes, so "stealing" a handful (4 or 8 bytes for a pointer) at the end has a negligible impact (low overhead).
Once the first block (head, address 2000) in the list is located, reading the next pointer tells us where the next block is. It is just a matter of reading memory to get the next pointer, so it's very fast. We just continue following the next pointers until we reach the end. Since memory is very fast, traversing the list in memory is efficient.
None of this information is new or enlightening to anyone reading this. However, when the nodes (blocks) are on the disk and not in memory, that's when things get interesting (and glacially slow) so a different technique is required.
Suppose each block of data contains 500 bytes of data. The five blocks combined gives us 2,500 bytes of data. This is where the bytes are stored:
Now, imagine that those 5 blocks of data are stored on a disk instead of memory. We'll use the same addresses for demonstration purposes. How much effort (read: disk access) is required to read the 5 blocks? The algorithm is the same as before, except instead of reading the next pointers from memory, we have to read them from the disk. Since the disk is 1,000 times slower (again, that's being generous) than memory, it takes 1,000 times longer to read all of the next pointers! That will make any program completely unusable. 60 frames per second? Try more like 0.06 fps.
The fundamental problem with this strategy (when the blocks/nodes are on the disk) is that we have to read the entire block in order to get the next pointer. And reading disk blocks is extremely slow. We are spending way too much time reading unnecessary data just to get to the next pointers.
Of course, we still have to read the next pointers from the disk, but we can read a lot of them (maybe thousands at-a-time) with one disk read and then traverse them in memory instead of reading each one from disk. Once we find the one we need, we can then just make one additional disk read to get the byte(s) we're interested in.Here's an idea: What if we separated the data from the next pointers and kept the data (very large) on the disk and kept the next pointers (very small) in memory? That's where the file allocation table comes in.
Back to the original problem:
Filesystem Tools
At this point, we have a very rudimentary filesystem in place. There are really only two things that you can do with it and they are:Also, we are tracking very little information about each file. In fact, we only track the name and size. We don't keep track of times, dates, owner/group, types (e.g. executable, directory), permissions like read/write, etc. This was just to keep things very simple at the beginning. Later, you will see how to easily add some of this information. We also don't have subdirectories; every file is in the same "global/root" directory, not unlike some older filesystems that didn't have anything but a single, root directory. MS-DOS didn't support hard disks or subdirectories until version 2.0. (It only supported floppies before then and all files were in the "root" directory.)
Some other things we'd like to do at this point.
This shows the type, permissions, owner, group, size, date, time, and filename. Our simple filesystem will only be able to display a size and a name.-rw-r--r-- 1 chico chico 12,401 Nov 28 15:31 driver.c -rw-r--r-- 1 chico chico 12,884 Nov 28 18:49 dumpvfs.c -rw-r--r-- 1 chico chico 7,423 Nov 27 17:28 mkvfs.c -rw-r--r-- 1 chico chico 9,138 Nov 26 17:37 vfs.c
This gives us more detail about the file's storage. The inode is somewhat analagous to the file allocation table (FAT) that we are using.File: vfs.c Size: 9138 Blocks: 24 IO Block: 4096 regular file Device: 805h/2053d Inode: 1844721 Links: 1 Access: (0644/-rw-r--r--) Uid: ( 1000/ chico) Gid: ( 1000/ chico) Access: 2021-11-29 16:21:59.648300925 -0800 Modify: 2021-11-26 17:37:16.017421021 -0800 Change: 2021-11-27 19:34:19.123915757 -0800 Birth: -
ID: 1938f8db12bca83c Namelen: 255 Type: ext2/ext3
Block size: 4096 Fundamental block size: 4096
Blocks: Total: 25066860 Free: 16391150 Available: 15107054
Inodes: Total: 6406144 Free: 5900127
If we have a very large file, we will have to locate all of the blocks (in order) and display the contents of each, one after the other.Roses are red. Violets are blue. Some poems rhyme. But not this one.
or df -h (human-readable)Filesystem 1B-blocks Used Available Use% Mounted on /dev/sda1 58,787,778,560 26,084,511,744 29,686,591,488 47% / /dev/sda5 102,673,858,560 35,536,543,744 61,877,657,600 37% /home /dev/sdb1 206,289,469,440 40,816,304,128 154,970,628,096 21% /backups /dev/sdb2 777,949,659,136 31,258,271,744 707,150,217,216 5% /extra /dev/sdc1 1,968,874,242,048 1,315,211,378,688 553,626,198,016 71% /storage
Filesystem Size Used Avail Use% Mounted on /dev/sda1 55G 25G 28G 47% / /dev/sda5 96G 34G 58G 37% /home /dev/sdb1 193G 39G 145G 21% /backups /dev/sdb2 725G 30G 659G 5% /extra /dev/sdc1 1.8T 1.2T 516G 71% /storage
Some of these features would be for "normal" users (e.g. renaming) and others would be used by an administrator (e.g. checking corruption, defragging) or for debugging by a developer (e.g. displaying the FAT).
Development Tools
Now that you are working with structured binary files, you may need additional custom tools to help you prove to yourselves that your output is correct. This is especially true with binary files. Text files are completely human-readable and so we never needed any special tools to view them. We would generate output and could tell just by looking at it (sometimes) if it was correct. For complicated text output, we used a diff tool to help us find the differences.However, with binary files, it's more work because we can't just look at the files (easily) to see the differences, nor can we use a text-based diff tool (easily). Fortunately, there are a few tools that we can use.
Here are some suggested tools that I used or created during development of the filesystem:
will produce a text version of the binary file. Do this with any of the input and output filesystems then you can use diff. Here's the help screen from the program: (The color probably won't work on Windows.)dumpit vfs3.fs > vfs3.txt
dumpit version 1.01 Usage: dumpit [options] [file1 file2 ...] Options: -c --color Use colorized output. -lX --length=X Stop after printing X characters. (Default is entire file.) -oX --offset=X Start at byte X in the file. (Default is 0.) -v --version Display the version and quit. -wX --width=X How wide the output is. (Default is 16 chars.) -h --help Display this information. If no input files are specified, read from stdin.
gives this output:./dumpvfs vfs.fs
Filesystem label: 'fat'
Filesystem type: FA
Filesystem size: 526624 bytes
Size of SuperBlock: 32 bytes
Size of FAT: 2048 bytes
Size of directory area: 256 bytes
Size of data area: 524288 bytes
Sectors in filesystem: 1024
Bytes per sector: 512 bytes
Sectors per block: 1
Max number of files: 16
Largest file allowed: 524288 bytes
Data sectors in use: 84
Data sectors available: 940
Data blocks in use: 84
Data blocks available: 940
Files in use: 5
Files remaining: 11
Size of files: 41942 bytes
Space consumed by files: 43008 bytes
Percent usage (blocks): 8.20%
Percent usage (bytes): 8.00%
Internal fragmentation: 2.48%
External fragmentation: TBD
mkvfs version 1.00 Usage: mkvfs [options] [file1 file2 ...] Options: -sX --total-sectors=X The total number of sectors in the data area. (Default: 16) -bX --bytes-per-sector=X The number of bytes per sector. (Default: 16) -cX --sectors-per-cluster=X The number of sectors per cluster. (Default: 1) -dX --directory-entries=X The total number of directory entries. (Default: 4) -lX --label=X The filesystem label. (Default: "SFAT") -fX --fstype=X The filesystem type. (Default: 0xFA) -oX --output=X The name of the file to create. (Default: vfs.fs) -h --help Display this information. If no input files are specified, an empty filesystem is created.
Example: Suppose there are two files: pic.png (2395 bytes) and decl.txt (2037 bytes). To create a filesystem that includes both of those files, you could execute a command like this (long and short options):
./mkvfs --total-sectors 12 --bytes-per-sector 512 --directory-entries 8 --output vfsx.fs pic.png decl.txt ./mkvfs -s12 -b512 -d8 -o vfsx.fs pic.png decl.txtOutput:Running dumpvfs on the output file:filename: vfsx.fs total_sectors: 12 bytes_per_sector: 512 sectors-per-block: 1 directory-entries: 8 label: SFAT fs-type: FA Number of files: 2 File 001: pic.png File 002: decl.txtFilesystem label: 'SFAT' Filesystem type: FA Filesystem size: 6328 bytes Size of SuperBlock: 32 bytes Size of FAT: 24 bytes Size of directory area: 128 bytes Size of data area: 6144 bytes Sectors in filesystem: 12 Bytes per sector: 512 bytes Sectors per block: 1 Max number of files: 8 Largest file allowed: 6144 bytes Data sectors in use: 9 Data sectors available: 3 Data blocks in use: 9 Data blocks available: 3 Files in use: 2 Files remaining: 6 Size of files: 4432 bytes Space consumed by files: 4608 bytes Percent usage (blocks): 75.00% Percent usage (bytes): 72.14% Internal fragmentation: 3.82% External fragmentation: TBD
Output:./statvfs vfsx.fs pic.png
If you don't provide a file from the filesystem, all files are processed:File: pic.png Size: 2395 Blocks: 5 IO Block: 512 FAT entry: 0 On disk: 2560 Wasted: 6.45% Sectors: 0 1 2 3 4
Output:./statvfs vfsx.fs
File: pic.png Size: 2395 Blocks: 5 IO Block: 512 FAT entry: 0 On disk: 2560 Wasted: 6.45% Sectors: 0 1 2 3 4 File: decl.txt Size: 2037 Blocks: 4 IO Block: 512 FAT entry: 5 On disk: 2048 Wasted: 0.54% Sectors: 5 6 7 8
Output:./lsvfs vfs9.fs driver.c
If you don't provide a file from the filesystem, all files are processed with a summary at the end:Blocks Size Name [ 31] 15550 driver.c
Output:./lsvfs vfs9.fs
Blocks Size Name [ 5] 2395 pic.png [ 4] 2037 decl.txt [ 1] 69 poem.txt [ 48] 24265 notes.odt [ 220] 112522 Doxyfile [ 31] 15550 driver.c [ 92] 47036 typescript [ 107] 54714 foo.c File count: 8, Blocks used: 508, Size in bytes: 258588, Size on disk: 260096, Overhead: 0.6%
Output:./catvfs vfs9.fs poem.txt
This command:Roses are red. Violets are blue. Some poems rhyme. But not this one.
creates a file in the "real" filesystem called foo.png. It contains the contents of the file pic.png from the SFAT filesystem called vfs9.fs. The command:./catvfs vfs9.fs pic.png > foo.png
shows this:ls -l foo.png
which shows that it is the same size as what's in vfs9.fs. You can now view the image file with any image viewer.-rw-r--r-- 1 mmead mmead 2,395 Mar 30 13:23 foo.png
The Big Picture
OK, so how realistic is this filesystem design? In theory, it's a sound starting place for a usable, albeit, inefficient way to store large numbers of files. In practice, it would be too inefficient for all but the smallest systems. However, by understanding the implementation of this simple filesystem you can begin to see how more sophisticated systems can be built.Let's see what we can, and more importantly, cannot do with our current implementation.
Well, that's a humbling list!
Our Implementation Real-World™ Implementations
So, although our filesystem does almost nothing, you can easily see how you might extend it to support features found in modern filesystems. In fact, here are some questions for you to answer about this simple filesystem. How would you support:
References
Links