Linked Lists
Pros:Skip Lists (High-Performance Linked Lists)
The fundamental problem with linked lists is that during a search, we must look at every node in the list that comes before the target node, even if the list is sorted. (No binary search methods are possible.)Searching for T in the list below requires looking at 12 nodes before reaching the node with T. We would pass through B, C, E, G, H, I, K, L, M, P, R, S then we would reach T.
If we create some nodes with 2 pointers, we can have them point "further" into the list, say 2 nodes ahead. This let's us traverse 2 nodes at a time, effectively cutting the number of node traversals in half. We would look at C, G, I, L, P, S, V then "back up" to S, and then traverse the "normal" pointer to reach T.
We can take this notion further and move ahead 4 nodes at a time instead. Now we'd look at G, L, S, Y, then backup to S to reach T.
or 8 nodes at a time, looking at L and Y, backing up to L, and then traversing through M, P, R, S to reach T.
Showing the traversed links as darker lines and the non-traversed but compared links as dotted lines:
In the above list, the nodes we would have to look at are L, Y, S, V, T. (We'd actually look at Y twice.)
By having multiple next pointers, we can vary the speed at which we move through the list. Kind of a built-in fast-forward mechanism. Locating an item is a very simple:
A skip list keeps the data sorted so we don't have to look at every element. This is also why a binary search through a sorted array doesn't require looking at every element. The same is true of a balanced BST.
Structure of a Skip List
There are several key factors involved in building a skip list:In the diagram above, at level 0 we have the next (and previous) pointer. At level 1, we have forward pointers that jump two nodes at a time. Level 2 forward pointers jump 4 nodes at a time and the forward pointers at level 3 jump 8 nodes at a time.
Given the scheme above:
Pointers required (for a double-linked list):
This doesn't account for the data itself. Also, as we'll see, we will want to store the level of the node (an integral value).
With this scheme above, there are N links at level 0 (2N if doubly-linked), N/2 links at level 1, N/4 links at level 2, N/8 links at level 3, and N/2L links at level L, which gives us (assuming single-linked at level 0)
N + N/2 + N/4 + . . . = N(1 + 1/21 + 1/22 + 1/23 . . .) = N(1 + 1/2 + 1/4 + 1/8 . . .) = 2NIn this example, we've been using a skip factor of 2, meaning that each successive level skips over 2 times as many nodes as the previous level. We can set our skip factor to any number, such as 3 or 4. Using t as our skip factor, the equations become:
N/t0 + N/t1 + N/t2 . . . = N(1 + 1/t1 + 1/t2 + 1/t3 . . .) = (t / (t - 1))N
Based on the skip factor, the number of pointers required is:
With an arbitrary skip factor, we have this: (SF is the skip factor, N is the number of nodes, and L is the level)t Pointers -------------------------- 2 2N 3 3N/2 4 4N/3 5 5N/4 6 6N/5
which is the number of nodes at each level. Plugging values into N, SF, and L in the equation gives us these numbers:(SF - 1)N ----------- SFL+1
With a list of 262,144 (256K) nodes, we'd expect to see this distribution of nodes at each level:
| Skip factor 2 | Skip factor 4 |
|---|---|
Level 0 nodes: 131072 Level 1 nodes: 65536 Level 2 nodes: 32768 Level 3 nodes: 16384 Level 4 nodes: 8192 Level 5 nodes: 4096 Level 6 nodes: 2048 Level 7 nodes: 1024 Level 8 nodes: 512 Level 9 nodes: 256 Level 10 nodes: 128 Level 11 nodes: 64 Level 12 nodes: 32 Level 13 nodes: 16 Level 14 nodes: 8 Level 15 nodes: 4 Level 16 nodes: 2 Level 17 nodes: 1 |
Level 0 nodes: 196608 Level 1 nodes: 49152 Level 2 nodes: 12288 Level 3 nodes: 3072 Level 4 nodes: 768 Level 5 nodes: 192 Level 6 nodes: 48 Level 7 nodes: 12 Level 8 nodes: 3 Level 9 nodes: 1 |
Level Nodes at level N
---------------------------
0 1
1 2
2 4
3 8
4 16
5 32
6 64
7 128
8 256
9 512
10 1024
11 2048
12 4096
13 8192
14 16384
15 32768
16 65536
17 131072
Implementation Details
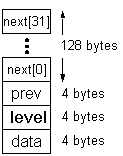
For these examples, we'll assume that the data is simply a 4-byte void pointer (32-bit computer):
const unsigned MaxSkipLevels = 32; // can skip 4 billion nodes!
typedef struct SLNode* SLNodeArray[MaxSkipLevels];
struct SLNode
{
void *data; // The arbitrary data in the node
unsigned level; // The type (level) of node (0 to MaxSkipLevels - 1)
SLNode *prev; // Previous pointer (assume doubly-linked at level 0)
SLNodeArray next; // Array of "forward" pointers, including the "next" pointer at level 0
};
Note: Although the structure above appears to have a lot of wasted space, we won't ever actually create an SLNode directly. We will allocate "raw" memory and treat it (cast it) as an SLNode.
Memory-efficient code to allow variable-sized SLNode structures:
SLNode created by declaration
(32-bit pointers)SLNodes representing different levels
(32-bit pointers)
// C++ code // sizeof(SLNode) is 140 SLNode node;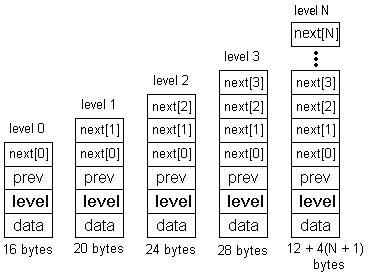
SkipList::SLNode* SkipList::allocate_node(unsigned level) const
{
// On 32-bit computer: sizeof(data) + sizeof(level) + sizeof(prev) = 12
unsigned size = sizeof(data) + sizeof(level) + sizeof(prev) + (level + 1) * sizeof(void *);
SLNode *node = 0;
try
{
node = reinterpret_cast<SLNode *>( new char[size] );
}
catch (const std::bad_alloc &)
{
throw SLException(SLException::E_NO_MEMORY, "allocate_node: Out of memory");
}
// initialize fields
node->level = level;
node->prev = 0;
// Never use memset when setting pointers to 0
for (unsigned int i = 0; i <= level; i++)
node->next[i] = 0;
return node;
}
Since most (94%) of the nodes are less than level 4, this wastes far too much memory.node = new SLNode; // allocates 140 bytes for all nodes in the list
Inserting into a Skiplist
Suppose we want to insert U into this list:We can easily find where to insert U: between T and V. However, this leads us to other questions:
Looking at the (perfect and unrealizable) list above, we can see the distribution of nodes. Given a list with N nodes, at each level we'd expect to see N / 2L + 1, where L is the level. So, given the 16 nodes above, we'd expect:
Node
Level Count Frequency Nodes
----------------------------------------------------------
0 8 0.5 (1/2 or 50% ) B E H K M R T X
1 4 0.25 (1/4 or 25% ) C I P V
2 2 0.125 (1/8 or 12.5% ) G S
3 1 0.0625 (1/16 or 6.25%) L Y
Level Nodes Frequency -------------------------------- 0 8192 0.5 1 4096 0.25 2 2048 0.125 3 1024 0.0625 4 512 0.03125 5 256 0.015625 6 128 0.0078125 7 64 0.00390625 8 32 0.001953125 9 16 0.0009765625 10 8 0.00048828125 11 4 0.000244140625 12 2 0.0001220703125 13 1 0.00006103515625
Ok, so what kind of node do we create when we insert an item?
Code similar to this below would be used during the insertion phase. For simplicity, assume that skipFactor_ is 2:
// calculate the level for the new node
unsigned Level = 0; // assume a level 0 node
double d = drand(); // "roll the dice" (returns random number 0 < x < 1)
// maxLevel_ is the largest node currently constructed
// and is initilized to 0 in the constructor.
while ( (Level <= maxLevel_) && (d < (1.0 / skipFactor_)) )
{
Level++;
d = drand(); // produces a number between 0 and 1
}
// if we've gone beyond the maximum level, raise the max
if (Level > maxLevel_)
maxLevel_++;
// allocate the new node calling the function above
SLNode *NewNode = allocate_node(Level);
Sample run of 256K items:The reason for the Level <= maxLevel_ above is to constrain the size of the largest node. If we have a small number of items in the list, we don't want (or need) large nodes that can skip over large numbers of items. However, as the number of items grows, the size of the largest node (maxLevel_) will increase.
Statistics with skip factor: 2
Ideal Actual Ideal Probability Actual Probability
---------------------------------------------------------------------------------
Level 0 nodes: 131072 133590 50% 50.960540771484375%
Level 1 nodes: 65536 65926 25% 25.148773193359375%
Level 2 nodes: 32768 31846 12.5% 12.148284912109375%
Level 3 nodes: 16384 15630 6.25% 5.962371826171875%
Level 4 nodes: 8192 7652 3.125% 2.91900634765625%
Level 5 nodes: 4096 3859 1.5625% 1.4720916748046875%
Level 6 nodes: 2048 1816 0.78125% 0.69274902343749989%
Level 7 nodes: 1024 958 0.390625% 0.36544799804687506%
Level 8 nodes: 512 426 0.1953125% 0.162506103515625%
Level 9 nodes: 256 223 0.09765625% 0.0850677490234375%
Level 10 nodes: 128 106 0.048828125% 0.040435791015625%
Level 11 nodes: 64 61 0.0244140625% 0.0232696533203125%
Level 12 nodes: 32 24 0.01220703125% 0.0091552734375%
Level 13 nodes: 16 13 0.006103515625% 0.0049591064453125%
Level 14 nodes: 8 10 0.0030517578125% 0.003814697265625%
Level 15 nodes: 4 3 0.00152587890625% 0.0011444091796875%
Level 16 nodes: 2 1 0.000762939453125% 0.0003814697265625%
Total nodes: 262144
Total pointers: 513961
pointers/nodes: 1.9606
Also remember the Fundamental Tenet of Computer Science:t Pointers -------------------------- 2 2N 3 3N/2 4 4N/3 5 5N/4 6 6N/5
Throwing more memory at a problem often speeds up the solution.
Insert a Node
The original list:
Inserting U:
As a level 0 node:
As a level 1 node:
As a level 2 node:
As a level 3 node:
As a level 4 node:
A couple of issues with inserting that's different from a "regular" linked list:
Deleting a Node
The current list:Deleting S from the list:
Like insertion, we need to keep track of all of the nodes that led to the new one so that we can update the pointers correctly. Like many other data structures, deleting an item usually entails a little more work than insertion.
There is only slightly more work to be done due to the fact that not all of the nodes that lead to the deleted node were traversed during the find. In the example above, nodes P and R need to be updated, yet they didn't lead to S.
Notes:
From the inventor's white paper:
Skip list paper written by the inventor (William Pugh). (.pdf document)
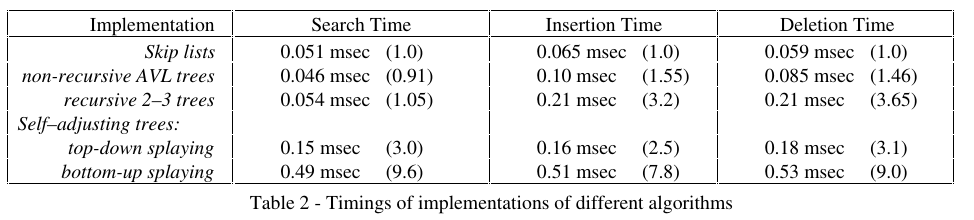
Google Groups Red-Black vs. SkipListSkip Lists: A Probabilistic Alternative to Balanced Trees: Skip lists are a data structure that can be used in place of balanced trees. Skip lists use probabilistic balancing rather than strictly enforced balancing and as a result the algorithms for insertion and deletion in skip lists are much simpler and significantly faster than equivalent algorithms for balanced trees.
Also from the paper: Implementation difficulty - For most applications, implementers generally agree skip lists are significantly easier to implement than either balanced tree algorithms or self-adjusting tree algorithms.
CONCLUSIONS - From a theoretical point of view, there is no need for skip lists. Balanced trees can do everything that can be done with skip lists and have good worst-case time bounds (unlike skip lists). However, implementing balanced trees is an exacting task and as a result balanced tree algorithms are rarely implemented except as part of a programming assignment in a data structures class. Skip lists are a simple data structure that can be used in place of balanced trees for most applications. Skip lists algorithms are very easy to implement, extend and modify. Skip lists are about as fast as highly optimized balanced tree algorithms and are substantially faster than casually implemented balanced tree algorithms.
Additional Diagrams
Inserting 'S'
Locating the position to insert S into the list. The thick black lines represent pointers in nodes that WILL be affected by the insertion of a new node. This is regardless of the size of the new node. (All nodes are at least at level 0.) The thick red lines represent pointers in nodes that MAY be affected by the insertion of a new node. This will depend entirely on the size of the new node which can be any size from 0 to MaxLevel + 1.
MaxLevel is currently set to 4. This is the level where the search for S will begin from the head node. Assume we have a method called locate that is used to find a node, or the position in the list where a new node will go. The method must keep track of the affected nodes. In this case, the SLNodeArray will contain pointers to head, head, L, L, P, R. These pointers will reside at index 5 through 0, respectively. Assuming a function called locate, which locates the position for the new node and fills in an array called BeforeNodes, this is what the BeforeNodes array should look like: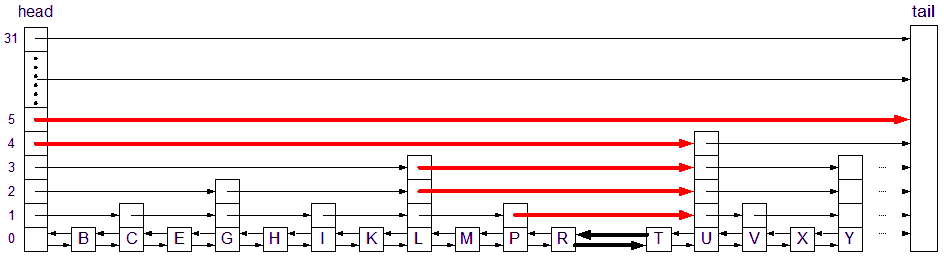
Before calling locate After calling locate 

If the level of the new node happens to be 3 (randomly chosen based on the ideal distribution of nodes), then only 4 of the 6 potential pointers will be affected. The thick black lines represent existing pointers that need to be modified in response to the level 3 node that was inserted. The blue lines represent the pointers in the new node that need to be setup.
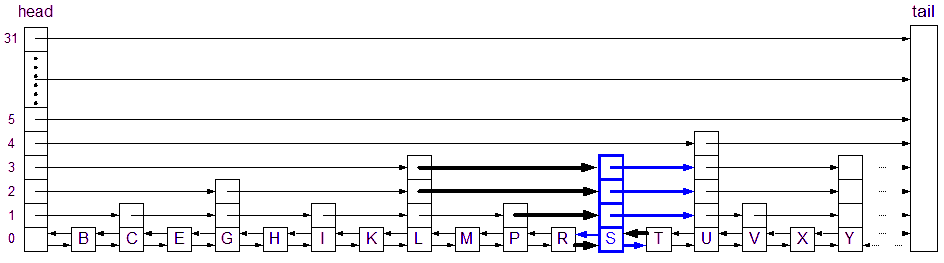
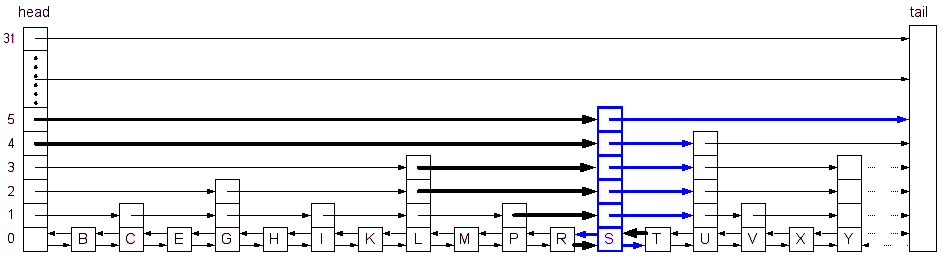
If, however, the level of the new node happens to be 5 (again, randomly chosen), then all 6 of the potential pointers will be affected (and MaxLevel will be increased to 5):
Deleting 'S'
As with inserting, we need to first locate the position where S resides in the list.Assuming we added a level 3 node: The thick black lines represent pointers in nodes that WILL be affected by the deletion. Notice that the number of pointers affected is different for the delete operation. Unlike with insertion, we know exactly which pointers will be affected because we know the size (level) of the node being deleted.
MaxLevel is still set to 4 so we will begin the search from this level. Again, the locate method will fill in the array of affected nodes. In this case, the SLNodeArray will only contain one non-head pointer. This pointer will always be at the highest level pointing to the node. In this case, since node S is a level 3 node, then only the pointer at level 3 in the BeforeNodes array will be changed.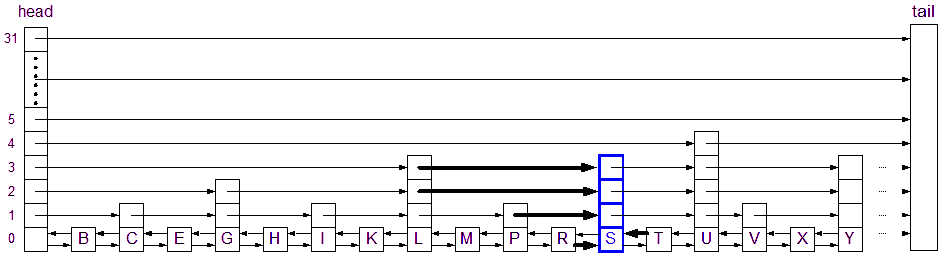
The search started at level 4 and looked ahead to U. Since U was larger than S, we had to step down to level 3. At level 3 we looked ahead to L. L is less than S, so we moved to node L. When we look ahead from L, we see S, which is the node we are looking for, so we set index 3 in the BeforeNodes to L.
This is what the BeforeNodes array should look like:
Before calling locate After calling locate 
This is where deletion differs from insertion. With insertion, our array of pointers included every node from the highest level down to 0. With deletion, we may not have traversed through every level to find the node. In fact, we only find the affected node at the level of the deleted node. This means that after finding the node to delete, we have to go back and fill in the rest of the BeforeNodes so it looks like this:
After calling locate After "fixing" the array Before deleting the node, you need to "hook up" the affected nodes. If you delete the node before hooking up the pointers, you won't know where to point the pointers. The diagram shows how the pointers are modified before the deletion:
Setting the pointers is as simple as copying the values from the deleted node, S in this case, to the affected nodes. This is done by copying the level 3 pointer to node L (at level 3), copying the level 2 pointer to node L, copying the level 1 pointer to node P, and copying the level 0 pointer to node R. The last step is to copy the previous pointer from S to the previous pointer in T.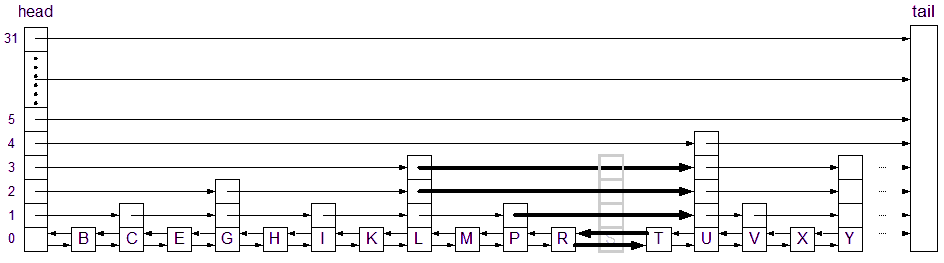
Finally, realize that, although I drew the pictures above showing the tail node as the maximum level, it really only needs to be a level 0 node:
The head node still requires all levels (not shown above) because it is pointing at other nodes. The tail node points at nothing. It is merely being pointed at by the other nodes and is used as a sentinel, marking the end. (Sometimes, using a separate tail-pointer can lead to simpler code.)